画像生成AIの現在
2024年夏時点では、画像生成が出来るAIは沢山あります。それぞれに特徴がありますが、独自視点で分類しました(代表的なものだけで、すべての製品を網羅していません。)。
開発目的が画像を生成するためのAI。
Stable Diffution系
StabilityAI社がオープンソースで公開したテキストから画像を生成するAI。これだけでは使いづらいため、GUIが独自に開発されました。
- Automatic1111
- ComfyUI
- Forge
また、Stable Diffusionをバックエンドで使用し、フロントにはブラウザでアクセスするサービスも多数展開されています。
いずれも画像生成はStable Diffusionが行います。
Midjourny
有料の独自画像生成AI。アニメ系に特化したNijijournyも展開。
DALL-E3
OpenAI社が開発している画像生成AI。
元々はテキストを学習したテキスト生成AIが、入力・出力に画像、動画、音声を使えるマルチモーダルに進化したもの。
- ChatGPT(OpenAI)内部でDALL-E3を使っている?
- Gemini (Google)
- Claude3(Anthropic)画像は入力のみ?
- Llama(Meta)
元々が画像編集ツールにAIで画像生成機能を追加したもの。
- Adobe Firefly ・・Photoshop、Illustratorへ展開
- Canva ・・バックはStable Diffusion?
- Figma
いずれもテキスト(プロンプトと呼ぶ文章)から画像を生成します。
Stable Diffusion
上記のように沢山ある画像生成AIから、どれを使うか選択の鍵になるのは
- 自由度が高い(選択枝が多すぎ?)
- 著作権へのアプローチ
- 価格
などがありますが、今回はStable Diffusionを選択します。
Midjournyでは有料プランのみ(お試しも無くなりました。)ですし、出力画像はプロンプトでしかコントロールできません。
Stable Diffusionでは、モデル選択、LoRAの追加など出力画像の自由度が一気に高くなります。
Stable Diffusionの歴史
Stable Diffutionが発表されたのが、2022年8月22日ですので歴史は2年しかありません。しかし、その間の進化は驚くほどです。
理由は、
- オープンソースで公開されたこと
- NovelAIからモデルがリークしたこと
だと思います。
オープンソースで公開されたからこそ、
- Automatic1111のようなGUI
- 著作権を無視したDanbooruの画像を学習したWaifu Diffusion
- 簡単な追加学習がユーザーレベルで出来るLoRA
- ポーズなどの指定ができるControlNet
- 独自学習のモデル、LoRAをシェアできるCivitAI
が登場し、自由度が高まると同時に分かりやすくなりました。
- 2022/8/22Stable Diffusion発表
クラウドでなく自分のPCで動く画像生成AIとして登場
- 2022/10Stable Diffusion 1.5
1.0がリリースされてから1.1、1.2、1.3、1.4とアップデートが続いたが安定し現在でも使われている1.5登場
- 2022/11Stable Diffusion 2.0
新しくトレーニングされた2.0登場、翌月2.1リリース
- 2023/7Stable Diffusion XL
35億パラメータのXLが登場
- 2023/11Stable Diffusion XL Turbo
XLを少ないステップで動作させるTurbo登場
- 2024/2Stable Diffusion 3
Medium、Large、Large Turboの3モデルで登場
このように急激に進化を続けるStable Diffusionですが、残念なことに1系列、2系列、XL系列、3系列とモデルやLoRAに互換性がありません。
バージョンが変わる度にモデルがゼロから作成されているため仕方ないこととは言え、過去の遺産が使えなくなるのは困りものです。
1.5系列は、NovelAIからのリークモデルを使い学習させたモデルが多数公開されていました。LoRAも同様です。
そのため、未だに1.5系を使い続ける人もいます(私です。)。
Stable Diffusionを使うために
Stable Diffusionはオープンソースで公開されているため、
- Python環境を構築
- ソースをダウンロード
- モデルをダウンロード
することで、自分のPCで動かすことができます。
ただし、それなりのメモリを搭載したビデオカード(NVidia推奨)が必須です。
AIで画像生成するために30万円以上するビデオカードを購入するよりも、安価なクラウドサービスを使う方が良いでしょう。
Python環境がスグに使えるクラウドサービスとして
- Google Colab
- Paperspace(Digital Ocean)
が手頃です。
Stability Development Platform
大量の画像を作成する場合であれば、上記のクラウドサービスがお勧めです。
ただ、そんなに大量の画像が必要ないのであれば、StabilityAI社が全て用意している「Stability Development Platform」を使えば簡単に最新のStable Diffusionが使えます。
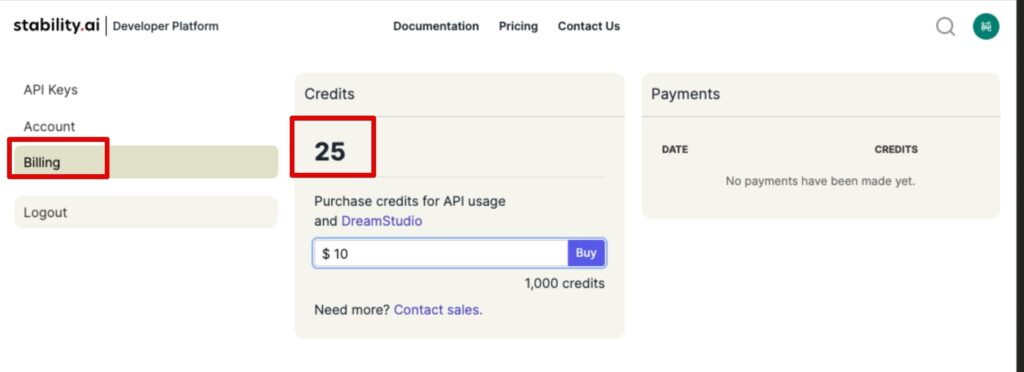
有料のサービスで、10米ドルで1,000クレジット購入となります。Stable Diffusion 3 Mediumの場合は、1画像6.5クレジットです。
つまり、10米ドルで153枚の画像を作成することができます。
アカウントを作成すると、25クレジットが付与されます。
Stability Development Platformアカウント作成
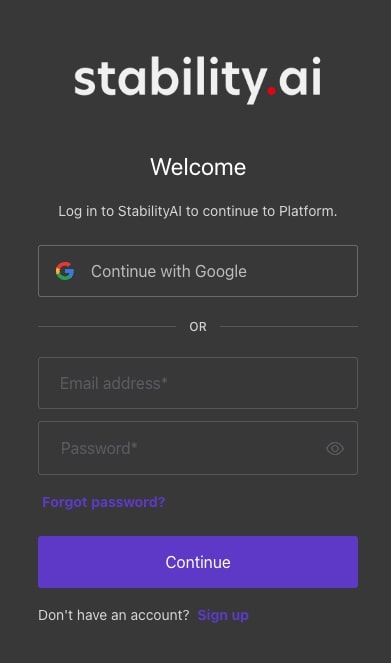
Stability Platformへアクセスし、右上のLongiをクリックします。

ログインダイアログが表示しますので、「Continue with Google」ボタンをクリックしてGoogleアカウントで続けます。
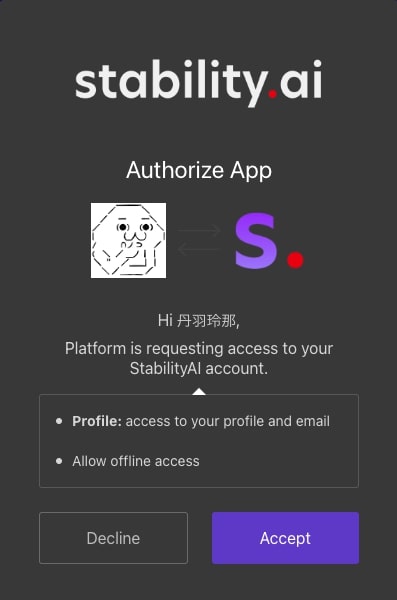
規約への同意を問われますので、「Accept」をクリックします。
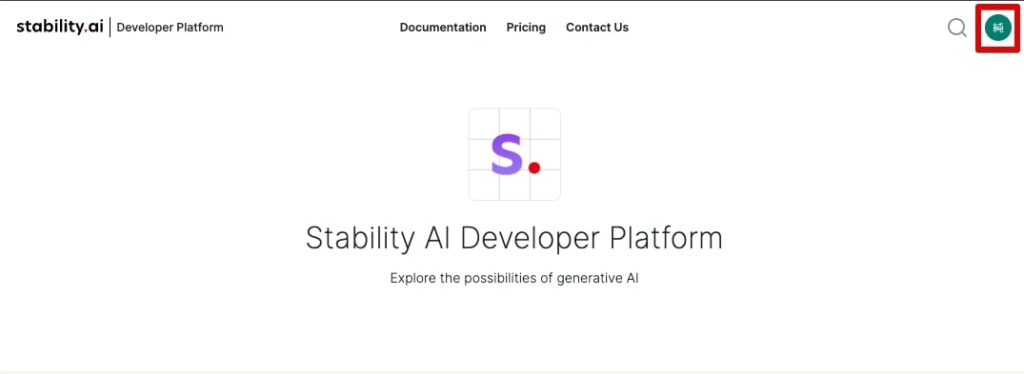
ログイン後、右上のアカウントアイコンをクリックします。
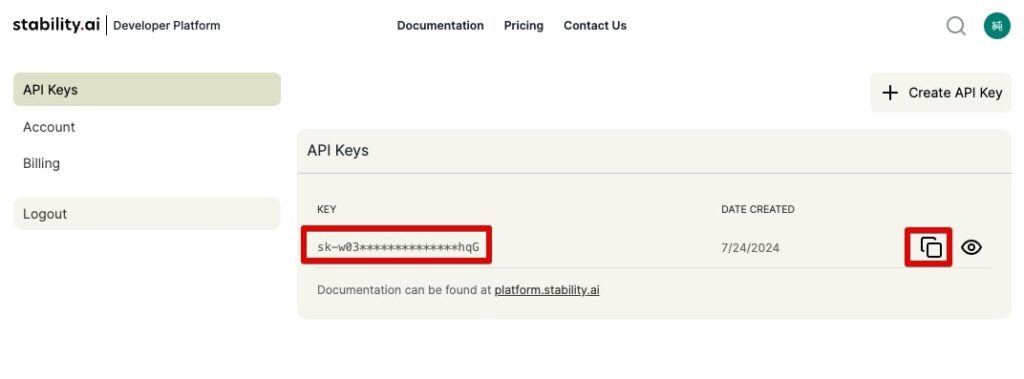
個人設定の画面になります。API Keysは自動で発行されます。右側のコピーボタンでコピーできます。
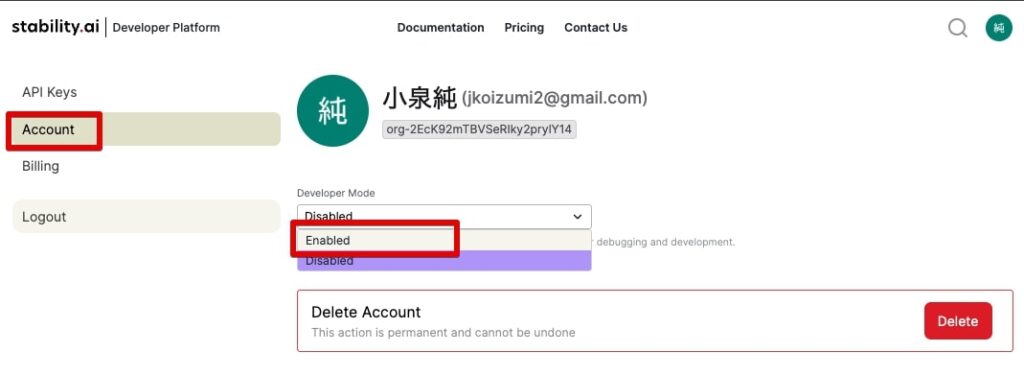
左メニューのアカウントをクリックし、Development Modeを「Enable」に換えます。
左メニューのBillingをクリックすると、現在のクレジットが表示されます。また、ここでクレジットの購入もできます。